Python数据分析-看了这篇文章,数据清洗你也就完全掌握了
发布时间:2019-09-11 22:26:27 所属栏目:教程 来源:哗啦圈的梦
导读:副标题#e# 所有做数据分析的前提就是:你得有数据,而且已经经过清洗,整理成需要的格式。 不管你从哪里获取了数据,你都需要认真仔细观察你的数据,对不合规的数据进行清理,虽然不是说一定要有这个步骤,但是这是一个好习惯,因为保不齐后面分析的时候发
|
副标题[/!--empirenews.page--]
所有做数据分析的前提就是:你得有数据,而且已经经过清洗,整理成需要的格式。 不管你从哪里获取了数据,你都需要认真仔细观察你的数据,对不合规的数据进行清理,虽然不是说一定要有这个步骤,但是这是一个好习惯,因为保不齐后面分析的时候发现之前因为没有对数据进行整理,而导致统计的数据有问题,今天小编就把平时用的数据清洗的技巧进行一个梳理,里面可能很多你都懂,那就当温习了吧! 文章大纲:
导入数据:
如何有效的导入数据: 1、限定导入的行,如果数据很大,初期只是为了查看数据,可以先导入一小部分:
2、如果你知道需要那些列,而且知道标签名,可以只导入需要的数据:
3、关于列标签,如果没有,或者需要重新设定:
4、设置索引列,如果你可以提供一个更有利于数据分析的索引列,否则分配默认的0,1,2:
5、设置数值类型,这一步很重要,涉及到后期数据计算,也可以后期设置:
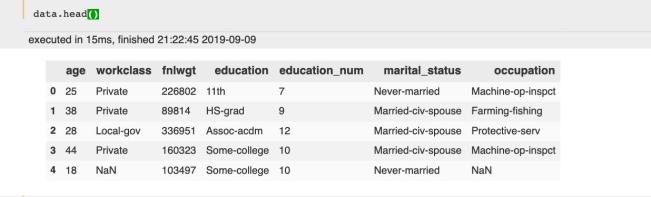
全面的查看数据:查看前几行:
查看末尾几行: 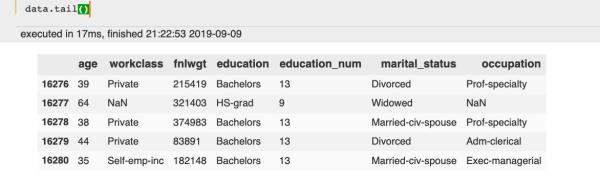 查看数据维度:
查看DataFrame的数据类型
查看DataFrame的索引
查看DataFrame的列索引
查看DataFrame的值
查看DataFrame的描述
某一列格式:
设置索引和标签:有时我们经常需要重新设置索引列,或者需要重新设置列标签名字: 重新设置列标签名:
重新设置索引:
重新修改行列范围:
取消原有索引:
处理缺失值和重复项:判断是否有NA:df.isnull().any() 填充NA:
删除含有NA的行:
删除含有NA的列:
(编辑:南平站长网) 【声明】本站内容均来自网络,其相关言论仅代表作者个人观点,不代表本站立场。若无意侵犯到您的权利,请及时与联系站长删除相关内容! |